
How to Speed Up Your SQL Database
Let’s have a look at the Filegroups feature in SQL Server
Today it’s time to get a little insight into the filegroups in SQL Server. But before we start, let’s set the basics.
Definition of Datafiles
A Datafile is a particular file in an SQL server. There are three types of database files
- Primary
- Secondary
- Log
The primary file contains the general startup data from your created database. This type is every time part of the database. It typically hast the file ending .mdf.
The secondary file type hast typically the ending .ndf. These files can be spread on multiple disks. For this, you can mix up the data to different types of disks.
The log file type contains all data to allow recovery of the database. Every database has one logfile it has the file extension called .ldf.
What are Filegroups
First of all, what’s a filegroup? A filegroup is an object in an SQL server that combines one or more data files to one “virtual” data file that can be assigned to each table or index or key definition. This constellation can only be done by secondary filetypes because the secondary filetypes are the only types, that can be combined by more than one.
Why use multiple data files?
Sure in a normal developer database, it won’t be necessary. Or when you start your Platform, in the beginning, it does not really matter. But think about, that your database grows in the near future. The database may become slow, you will lose customers, so also earnings. Okay, that’s a drastic story, but it can be the truth.
But let’s assume your database is very large and very busy, multiple files can be used to increase performance. Here is one example of how you might use multiple files.
Let’s say your database contains a single table with 10 million rows that are heavily queried.
If the table is in a single file (like in the schematic image above), such as a single database file, then SQL Server would only use one thread to perform a read of the rows in the table.
Now let’s add two more files, then the schematic will look like this:
So it’s now distributed over three files, in this case, the SQL Server would use three threads (one per physical file) to read the table, which potentially could be faster.
So you will get an enormous speed on your database when using this physical parallelism technique. So when you distribute the files like this
If each file were on its own separate physical disk or better a disk array, the performance gain would even be greater.
How to Extend Database with Filegroups
You can extend an existing database, with a custom filegroup if you want. For this, you can simply add the filegroup. But be careful, there are no connections to the Database allowed because you change some database infrastructure. Just switch to the master database with use master . Then you can add the filegroup with Alter Database MyDatabase Add Filegroup Data_FileGroup . In this case, you add a new filegroup named Data_FileGroup to your database MyDatabase .
Now you have a Filegroup, but now Diskspace is assigned for it. In this state, you cannot assign the filegroup to a table. In this case, let’s assume your Datafiles will be located in the directory /var/opt/data (used in Docker Image) then you can use this script to assign a Datafile to the Filegroup we created
ALTER DATABASE MyDatabase
Add FILE
(
Name=DataFile_1,
FILENAME='/var/opt/data/DataFile_1.ndf',
Size=1MB,
MaxSize = 100MB,
FileGrowth=5%
)
TO FILEGROUP Data_FileGroup
Now after execution, you can check, if the Filegrpoup was assigned to the database withSelect name, type_desc from sys.Filegroups
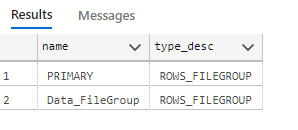
Assign Data to Filegroups
After you created the filegroups, you can then apply these to specific tables or index definitions. you must only append an ON Data_FileGroup after your definition. For example, if you want to create a table you can use the following syntax.
create table Customers(
id bigint,
name varchar(255),
firstname varchar(255)) on Data_FileGroup
You can get it more strict if you want the data on your Primary (Default) Filegroup and only the index Data on your Data_FileGroup, in this case, you can use this syntax
create table Customers(
id bigint,
name varchar(255),
firstname varchar(255),
CONSTRAINT PK_Customers_id PRIMARY KEY (Id) on Data_FileGroup,) on [PRIMARY]
Please pay attention to the [], because Primary is a reserved Keyword.
Rule of Thumb for Filegroups
I am no database engineer or DBA. But I think that three Filegroups are enough.
Primary— The default one, that will be createdLog— This will be created by the database creationINDEX— This Filegroup should be created by every developer. Because in this you can store all index relevant data, to get a boost on your queries.
Sure you can add more, I’ve seen that some architects create a HISTORY Filergoup, in that they store journaling data. That’s possible too, but at the first start, you can create these three groups.
Move existing Data to a new Filegroup
Unfortunately, there is no easy way to “migrate” data to another file group. As you know, the data is assigned to a physical file. So instead of simple switching, you must create a duplicate table, that would assign the new filegroup. Then you can copy the data into the newly created table. Then you must delete the old ones and set the relations to the new table then.


